Workshop 7 posters
Monday, 24th April 2023, 18:00 - …
The seventh workshop will host poster session dedicated to the presentation of new and ongoing projects in the field of Digital Epigraphy. We will also offer the possibility to present your poster virtually, and during the workshop the posters will also be displayed on the Epigraphy.info website (where they can be published publicly afterwards).
See all posters on Epigraphy.info GitHub
See the short video presentations on Epigraphy.info YouTube channel
List of posters:
- VALETE VOS VIATORES: new tools for teaching and disseminating Roman epigraphy
- Greek Metrical Inscriptions from the Imperial Age: A Website Proposal
- Linguistic Analysis in the Inscriptions of Israel/Palestine Project
- When epigraphy meets linguistics. The semantic annotation of modality in the Latin inscriptions of the Republican age.
- EpiSearch. Epigraphic Manuscripts and Digital Humanities.
- EpiDoc to CIDOC CRM alignment. Towards a semantic integration of epigraphic information
- Digitization of the inscriptions on the monuments of Armenian cultural heritage in Nagorno-Karabakh region
- Digital epigraphy and social media for master students: the example of Linear B tablets
- AGILe: the First Dedicated Lemmatizer for Ancient Greek Inscriptions
- Behind the scenes of the MAPPOLA Database
- Recognizing References to Ancient Sources in Modern Literature
- Epigraf: a research platform for the collection, annotation and publication of text data
- ENCODE: Creating training material for the study of ancient writing cultures & digital epigraphy
VALETE VOS VIATORES: new tools for teaching and disseminating Roman epigraphy
Javier Andreu Pintado, Universidad de Navarra, jandreup@unav.es
Abstract
As was presented in the last Epigraphy.info workshop, in the last two years, a consortium created by several European Universities, with the financial support of Creative Europe, has developed a project, Valete vos viatores: travelling through Latin inscriptions across the Roman Empire with an essential focus: to develop new tools and supports that contribute to highlight the role played by inscriptions in the Roman world and to use these tools as material supports for new forms of university teaching in Roman Epigraphy, among them, a large virtual repository of digitialized inscriptions, a video game, a documentary serie of four chapters explaining main goals on research in Roman Epigraphy and an open access final publication. The poster will present some of these supports as well as the website created for this purpose in case it is useful for teachers of Roman Epigraphy around the world.
Further information: https://www.unav.edu/web/valete-vos-viatores
Click here to see the full interactive poster(PDF)

Greek Metrical Inscriptions from the Imperial Age: A Website Proposal
Pietro Ortimini, University of Pisa
Abstract
A rich production of Greek epigraphic poetry flourished during the Imperial Age. A corpus of about 1700 Greek metrical inscriptions exhibits significant diversity in the geographical, socio-historical, archaeological contexts, and the literary aspects. As a part of my PhD research project, I am redefining the corpus by adding inscriptions not included in the current editions. Moreover, I am collecting the data relating to the geographical, socio-historical, archaeological contexts and the literary aspects for each inscription.
Over the next few years, I aspire to create a website where the inscriptions of the corpus are fully accessible as a single collection. The inscriptions will be placed on an interactive map, with references to the editions. The data relating to the socio-historical contexts and the literary aspects will be displayed for each inscription. The data are the following: the place of discovery, the epigraphic support, the date, the author, the clients and recipients, the literary genre, the length of the text, the type of meter. It will be also possible to carry out cross-searches thanks to a search index. The intention is to develop the website using Python and the Django web framework. The website will be HTML based, employ semantic markup based on XML, and include external links to the other epigraphy related websites. There are also plans to expand the database to include Greek metrical inscriptions from Late Antiquity (4th -6th century AD).
Click here to see the full poster(PDF)

Linguistic Analysis in the Inscriptions of Israel/Palestine Project
Christine Roughan (New York University), Christopher B. Zeichmann (Toronto Metropolitan University), Michael L. Satlow (Brown University)
Abstract
The Inscriptions of Israel/Palestine (IIP) project presents a digital corpus of inscriptions from Israel and Palestine dating between the sixth century BCE and the seventh century CE. As of April 2023, this corpus includes 5,282 inscriptions encoded in EpiDoc-compliant XML, an example of which can be seen in the XML excerpt to the right. Four languages comprise the bulk of the corpus: 2,941 of these inscriptions contain Greek, 1,739 contain Aramaic, 457 contain Hebrew, and 262 contain Latin. Other languages (Phoenician, Classical Armenian, Syriac, Arabic, and Georgian) are represented in smaller amounts.
Click here to see the full poster(PDF)

When epigraphy meets linguistics. The semantic annotation of modality in the Latin inscriptions of the Republican age.
Francesca Dell’Oro, Helena Bermúdez Sabel, Pauline Jacsont
Abstract
Modality – i.e., the expression of the notions of necessity, possibility and volition in a language – is today a thriving research field in linguistics. The WoPoss corpus is being set up and annotated with the goal of investigating modality in the history of the Latin language through literary and documentary texts. This poster outlines the new release of the WoPoss corpus, including now 74 inscriptions. This recent achievement crucially enriches the WoPoss corpus and complies with its aim of being a representative corpus in terms of sociolinguistic variables. Moreover, it enhances epigraphic research, by providing a fine-grained semantic analysis which is still rare even on literary texts.
In the poster we outline the whole pipeline along with the sequence of necessary file conversions, including the selection of the relevant Republican inscriptions to be (added and) retrieved from the EDR database, the automatic annotation of the files using the Stanza library for Python (adding lemmas, parts of speech, morphosyntactic description, and syntactic dependencies), the manual semantic annotation, the validation of the final files against the WoPoss project’s schemas and how the corpus can be accessed through the dedicated interface https://woposs.unine.ch/search.
Acknowledgements: This new release is the result of a close cooperation between the Epigraphic Database Rome project and the SNSF-funded project A World of Possibilities (PI: Francesca Dell’Oro). It was made possible by an EAGLE-IDEA bursary granted to Mrs. Pauline Jacsont.
Click here to see the full poster(PDF)

EpiSearch. Epigraphic Manuscripts and Digital Humanities.
Tatiana Tommasi
Abstract:
EpiSearch is a collaborative pilot project that explores the possibilities offered by technologies deployed in the field of the Digital Humanities to recover the data found in the so-called epigraphic manuscripts and to link them to the main online epigraphic databases existing today (EDR, EDH, EDCS, PHI). Epigraphic manuscripts, consisting of handwritten transcriptions made by erudites in post-classical times, are of fundamental value because they preserve the only record for textual sources that have not survived in their physical form. Despite their importance, epigraphic manuscripts have seldom received sufficient scholarly attention; moreover, until now they have never been studied through a digital approach. The EpiSearch project aims at bridging this gap.
To reach this goal the EpiSearch team is working on a case study: an epigraphic manuscript written in Venice in the early 1700s by a local antiquarian, Giovanni Antonio Astori. This study is intended as a proof of concept, in view of a future large-scale and collaborative research plan. The project has so far included three main steps.
The first one explores the possibilities offered by Handwritten Text Recognition (HTR) to study epigraphic manuscripts. The second encompasses designing an integrated system, created by collecting data from the main online epigraphic databases; this will give us the possibility to match the inscriptions that are transcribed in the manuscript with their edition in digital resources. The last step will produce a digital application to browse a visually annotated version of the manuscript with hyperlinks to the online epigraphic databases for connecting the transcriptions of inscriptions with their current digital editions.
The EpiSearch team includes Federico Boschetti: Institute for Computational Linguistics “A. Zampolli” – National Research Council of Italy (CNR-ILC), Pisa / Venice Centre for Digital and Public Humanities (VeDPH), Ca’ Foscari University of Venice; Lorenzo Calvelli, PI: Department of Humanities and VeDPH, Ca’ Foscari University of Venice; Franz Fischer: Department of Humanities and VeDPH, Ca’ Foscari University of Venice; Daniele Fusi: VeDPH, Ca’ Foscari University of Venice; Silvia Orlandi: Sapienza University of Rome; Thea Sommerschield: Department of Humanities, Ca’ Foscari University of Venice; Tatiana Tommasi: Department of Humanities, Ca’ Foscari University of Venice.
Click here to see the full poster(PDF)

EpiDoc to CIDOC CRM alignment. Towards a semantic integration of epigraphic information
Francesca Murano & Achille Felicetti
Abstract:
The poster presents the definition of the mapping between the EpiDoc encoding schema and CIDOC CRM, the most relevant ontology in the field of Cultural Heritage, provided by the ItAnt project.
The project “Languages and Cultures of Ancient Italy. Historical Linguistics and Digital Models” aims to investigate the languages of Ancient Italy by combining the traditional methods, proper to historical linguistics, with methods and technologies proper to the Digital Humanities.
The languages of ancient Italy are documented almost exclusively in epigraphic texts and the creation of the first digital archive of their documentation according to the TEI/EpiDoc Guidelines is one of the main objectives of the project.
In order to foster future interoperability and integration with other external datasets, a paramount concern of the project, we are mapping the EpiDoc schema to the CIDOC CRM ontology, in particular to its CRMtex extension, an ontological model developed to support the study of ancient documents by identifying relevant textual entities and by modelling the scientific process related to their investigation and features. CRMtex defines classes and properties for describing a handwritten text in all its aspects, from its creation in the past, down to its present conservation, investigation and study by scholars, including its transcription, translation, interpretation and publication.
The full compatibility of CRMtex with the CIDOC CRM ontology and its extensions ensures persistent interoperability of data encoded by means of its entities with other semantic information produced in Cultural Heritage and Digital Humanities.
Click here to see the full poster(PDF)

Digitization of the inscriptions on the monuments of Armenian cultural heritage in Nagorno-Karabakh region
Tamrazyan Hamest
Abstract
As part of a series of actions coordinated by the École Polytechnique Fédérale de Lausanne, the Digital Humanities Institute is currently prototyping methods to offer rapid deployment of DH technology in situations of crisis when a good network of local partners can be identified and coordinated. So far, we have collected, systematized and digitized more than two hundred inscriptions from the Nagorno-Karabakh region. By documenting, digitizing and annotating these inscriptions we strive to create a single readily searchable database of Armenian inscriptions of Nagorno-Karabakh complete with the essential information about them. However, the resources and methods of Digital Epigraphy have not yet been applied to Armenian inscriptions properly.
This project will be one of the first steps in this direction. It will help to point out the methodological issues which are specific to the application of information technologies to Armenian epigraphy. We assume that the computational approach is going to change the way Armenian epigraphy is studied, to the extent of renovating the discipline on the basis of new, unexplored questions.
Click here to see the full poster(PDF)

Digital epigraphy and social media for master students: the example of Linear B tablets
Elena Duce Pastor
Abstract
In this poster, I will present a project I am developing for the academic year 2022-2023 for master students in Antiquity. Concretely, in the subject “The Aegean in the bronze age: Minoans and Mycenaeans”. Students must study one Tablet in lineal B using online databases for bibliography and DAMOS database, which implies learning skills about digital epigraphy. Finally, they have to present their results in a Twitter file related to an official account (Antiquity from the University).
This Project implies the acquisition of digital humanities skills by students and the spread of this info to the general public. I try to teach them not only to be users of digital epigraphy but also to take into account public History.
Click here to see the full poster(PDF)

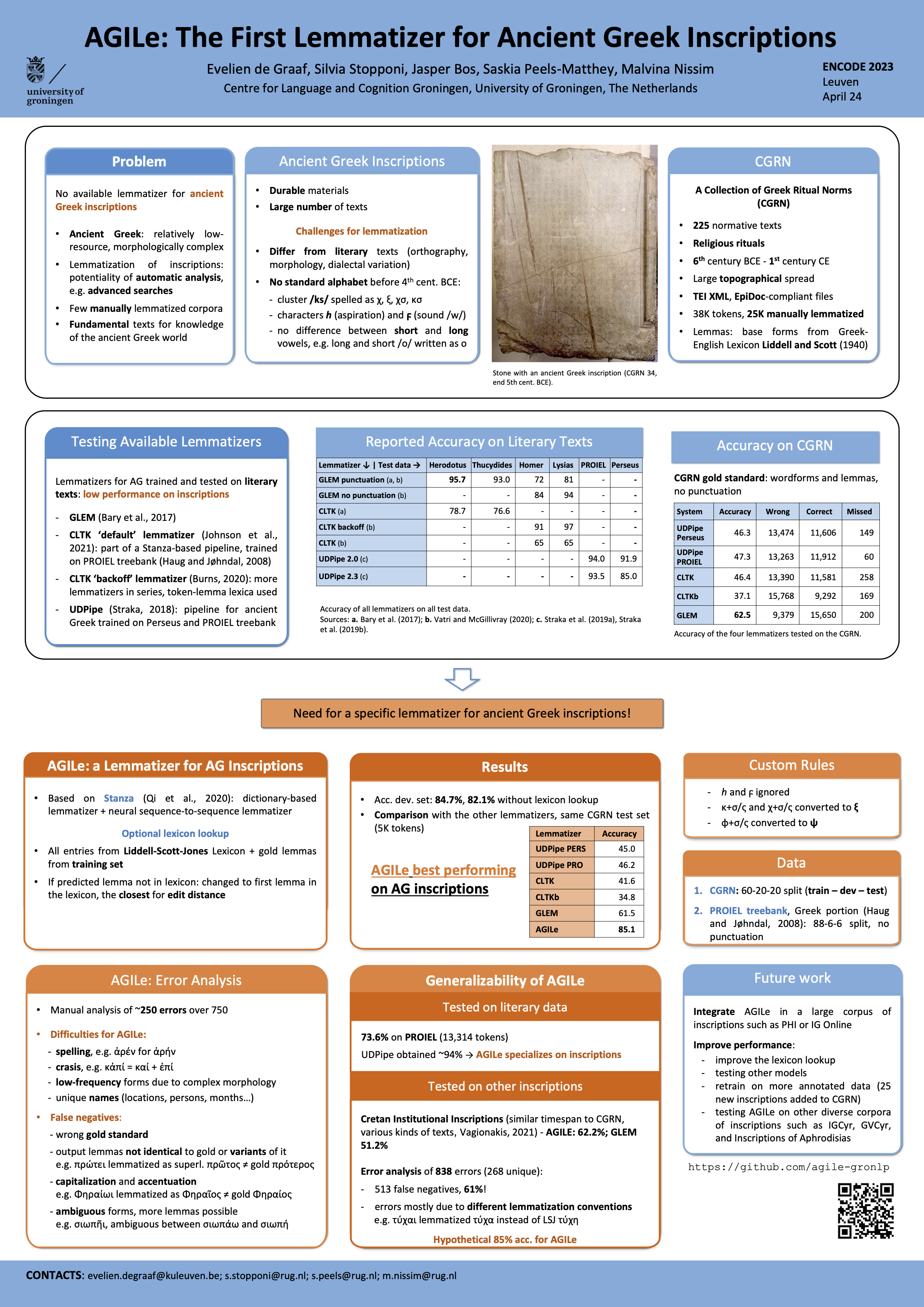
AGILe: the First Dedicated Lemmatizer for Ancient Greek Inscriptions
Evelien de Graaf, Silvia Stopponi, Jasper Bos, Saskia Peels-Matthey & Malvina Nissim
Abstract
Lemmatization (i.e. linking word forms to their lemmata) of Ancient Greek corpora is of key importance. Lemmatized texts allow for more advanced analyses, for example to easier retrieve (co)-occurrences and collocations, since it is possible to find all inflected forms of the same lemma with only one search. Despite these advantages, most corpora of Ancient Greek inscriptions have not been lemmatized yet. To remedy this problem, we present an automatic lemmatizer dedicated to inscriptions, which can achieve up to 85% accuracy. We first tested the performance of three available lemmatizers for ancient Greek, GLEM (Bary et al., 2017), the CLTK lemmatizer (Burns, 2020) and the UDPipe lemmatizer (Straka, 2019) on ancient Greek inscriptions. For evaluation, we used a manually lemmatized corpus, the Collection of Greek Ritual Norms project (Carbon et al., 2016), and compared the suggestions of these lemmatizers to the manually entered “gold” lemmata. Although reported performance of the lemmatizers on literary texts is around 90%, they perform worse (av. 46% correctness) on the CGRN, since they have been trained on, and are thus successful for literary texts, while epigraphical corpora come with specific challenges, notably, large (dialectal) variation and spelling mistakes.
We then created an automatic lemmatizer for inscriptions (called AGILe), learning directly from epigraphic material, thanks to recent advances in machine learning. Specifically, we trained the Stanza lemmatizer (Qi et al., 2020) on the CGRN, to obtain a lemmatizer tailored to epigraphy. We were able to increase the performance of automatic lemmatization, achieving almost 85% accuracy.
Bibliography
Bary, C., Berck, P., Hendrickx, I. (2017), A Memory-based Lemmatizer for Ancient Greek, in Proceedings of the 2nd International Conference on Digital Access to Textual Cultural Heritage, 91– 95.
Johnson, K. P., Burns, P. J., Stewart, J., Cook, T., Besnier, C., Mattingly, W. J. B. (2021), The Classical Language Toolkit: An NLP Framework for Pre-Modern Languages, in Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing: System Demonstrations, 20- 29.
Carbon, J-M., Peels, S., Pirenne-Delforge, V. (2016), A Collection of Greek Ritual Norms (CGRN), http://cgrn.ulg.ac.be/.
Straka, M., Straková, J., Hajič, J. (2019), Evaluating Contextualized Embeddings on 54 Languages in POS Tagging, Lemmatization and Dependency Parsing, ArXiv.Org Computing Research Repository, https://arxiv.org/abs/1908.07448.
Qi, P., Zhang, Y., Zhang, Y., Bolton, J., and Manning, C. D. (2020). Stanza: A Python natural language processing toolkit for many human languages, in Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics: System Demonstrations.
Click here to see the full poster(PDF)
Behind the scenes of the MAPPOLA Database
*Chiara Cenati, Alexander Gangoly, Victoria González Berdús, Peter Kruschwitz, Denisa Murzea, Rainer Simon, Paul Strobach & Mirko Tasso
Abstract
At the V Epigraphy.info workshop in 2020 we presented the idea of an open-access platform for the ERC-funded project MAPPOLA (Mapping out the poetic landscape(s) of the Roman empire) displaying the circa 4000 Latin and Greek verse inscriptions produced in the Roman world on an interactive map, according to various descriptors which include chronology, type of inscription, prosopographical features, language, etc. Now, almost three years later, we would like to show to the Digital Epigraphy community the progress we have made in the programming of the database and the technology we have adopted.
The database application is programmed in Python using the Flask framework. It loads and stores data from a relational database (MySQL) which we have given a specifically designed schema that fits our needs. We have used Eagle Vocabularies as far as possible and we have adapted them when necessary. For the bibliography we have set up a Zotero library which will be also extra referenced in the database. EpiDoc is used for the transcription of the epigraphic texts. For basic tags the Patrimonium EpiDoc converter has been implemented. Different visualizations of the diplomatic and interpretive transcription as well as the display of verse division have been obtained in EpiDoc.
Users will be able to display and filter the results of their search both as a list and on an interactive map which has been implemented. The technical basis for the map is MapLibre, an Open Source map library. Users will be able to switch between two different background layers, a present-day map based on OpenStreetMap data from the MapTiler hosting service, and the Digital Atlas of the Roman Empire map from the University of Gothenburg.
Click here to see the full poster(PDF)

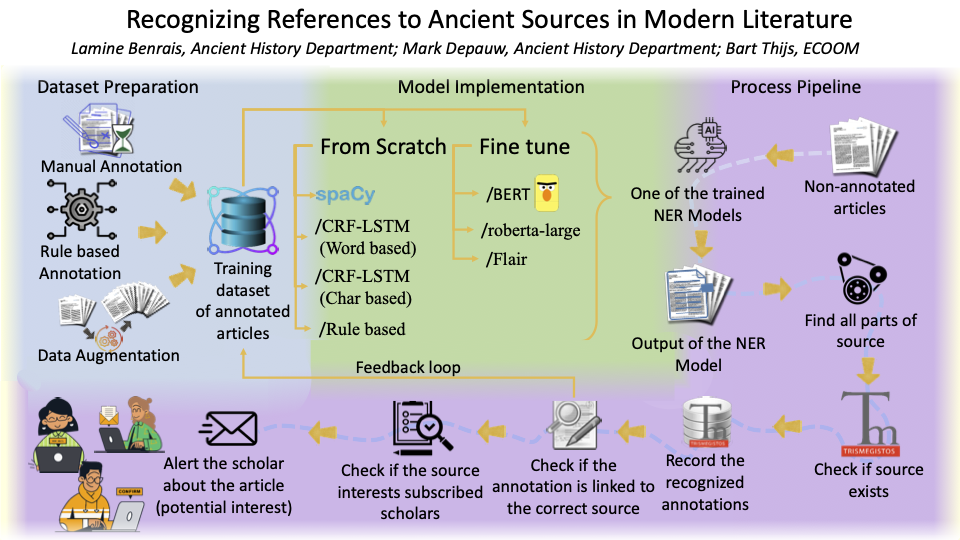
Recognizing References to Ancient Sources in Modern Literature
Lamine Benrais, Mark Depauw & Bart Thijs
Abstract
This project aims to provide scholars, peers and publishers the infrastructure to connect the more traditional scholarly literature and the world of digital tools. To do this, we develop and refine algorithms to distill references to ancient sources (inscriptions, papyri, authors, …) from articles and books stored as PDF. Combining a rule-based extraction system with existing gazetteers in Trismegistos, a gold standard will be established. This will then form the basis for more versatile and powerful machine learning techniques.
The references to the ancient sources will be harvested for bibliographic purposes but also the PDF will be annotated with a link to the Trismegistos database. This allows the Trismegistos website to offer users direct access to the ancient sources and to serve as a hub to related data and modern literature. As such the platform enhances interdisciplinarity, discloses sources to junior scholars and opens doors to new research opportunities.
Click here to see the full poster(PDF)
Epigraf: a research platform for the collection, annotation and publication of text data
Jakob Juenger
Abstract
Epigraf (https://epigraf.inschriften.net/) is a research platform that provides tools for the collection, edition, and structured data export of text data such as inscriptions, for instance for the publication of the ‘Deutsche Inschriften Online’ (DIO). Epigraf works with EpiDoc export and APIs to provide a better basis for further analyses and prepares data imports from other (national and international) projects to implement an open search solution for epigraphic data. In order to adjust the formats, the Epigraf team is interested in connecting to the larger epigraphic community, such as Epigraphy.info. If you would be interested in participating with own data, you are welcome to contact the PI of the project, Jakob Juenger.
Click here to see the full poster(PDF)

ENCODE: Creating training material for the study of ancient writing cultures & digital epigraphy
Alice Bencivenni, Federico Aurora, Marta Fogagnolo & Tom Gheldof
Abstract
This poster will present the results of the ENCODE project, a three-year (September 2020 - August 2023) Erasmus+ Strategic partnership for higher education, funded by the EU (partner universities: Università di Bologna, Universität Würzburg, KU Leuven, Università di Parma, Universitetet i Oslo). The ENCODE project aims at bridging the existing gap in the teaching/learning domain of ancient written cultures between the peculiar humanistic training and the now essential digital competences required for study, research and employment. It intends to promote digital competences among students and academic staff by developing innovative teaching modules with modern digital approaches and implementing them in the existing academic curricula.
The project stems from the awareness that specialised disciplines dealing with ancient written artefacts like epigraphy, papyrology and palaeography have increasingly embraced digital advancements, for instance by developing tools for new forms of participatory research and collaborative publishing. However, many scholars are still reluctant toward these innovations or require new competences and training in the rapidly evolving field of Digital Humanities and AI. To this end, the project organises conferences, workshops and training activities aimed at fostering awareness and knowledge of digital tools applied to the study of ancient cultural heritage. In particular, the partner universities organised seven Multiplier Events related to the study and digital treatment of ancient written artefacts followed by practical workshops and training activities involving international experts from different disciplines. From these training experiences, the partners have produced:
*a shared vocabulary of digital competences, learning outcomes and best practices in teaching and learning ancient writing cultures
*a database, which collects innovative and customizable teaching modules (basic and advanced) and improves participatory and intercultural approaches to the ancient written heritage
*a full guide to the teaching modules, including a MOOC, that will enhance the importance of innovative digital training and digital applications in the academic and professional environment
*a community network among employers, institutions concerned with digital curation (libraries, museums, publishers), professionals active in museums and libraries, academics, alumni and students who want to start their studies in the area of ancient history, languages and cultures
The shared vocabulary is based on two international reference frameworks, CALOHEE (for humanistic competences) and DigComp (for digital competences). They were used as input and inspiration for the development of the framework of digital competences, focused on teaching and learning about ancient writing cultures. A survey, conducted by the ENCODE partners and distributed via a questionnaire among participants (both teachers and students) of the workshops, provided us with the necessary examples of best practices for such teaching and learning activities in the field of ancient writing cultures.
The teaching modules, specifically developed for the ENCODE training events, were added to the ENCODE database, in order to stimulate the re-use of training materials and provide a possible pathway through which users can access different forms of digital training in the field of ancient writing cultures. The ENCODE database follows the classification in learning outcomes and competences, developed in the shared vocabulary, and adds one or more focus domains. By enabling a SPARQL endpoint, the database can be queried on either of these various parameters (modules, competences, focuses, …).
The ENCODE guidelines are developed to accompany these teaching modules and point to several innovative tools and methods that can be used to enhance digital competences in the field of ancient writing cultures. Additionally, a MOOC (massive open online course), also provides a different (“ideal”) pathway to this training. Organised as an online course on the dariahTeach platform, it offers the possibility to access - asynchronously - the different ENCODE training modules, while also referring to additional resources. The ENCODE course consists of 4 units with several lessons (‘Digital Epigraphy’, ‘Digital Papyrology’, ‘Multilingual-Multicultural Digital Infrastructures’ & ‘Linked Open Data for written artefacts’), including training materials and interviews with experts in the field.
Finally, the community network brings together alumni and stakeholders/employers from different communities, both in the study of ancient written artefacts and in the field of Digital Humanities. This should enhance the interconnection between these different disciplines, assuring a constant and dynamic contact among different actors and collecting professional opportunities. To this end, the partners tried to find a platform that could host this community and found it in the European GoTriple infrastructure and in the Trust Building System (TBS), a tool that enables researchers in Social Sciences and Humanities to connect with each other and find reliable partners. The output is still in progress and will be released at the end of the project: the platform will allow alumni to attach their accurate portfolio with a description of the digital competences achieved in the field of ancient writing cultures, the employers to disseminate occupational opportunities in the field and rely on for specific professional needs since they will rapidly find access to the kind of competence required.
Click here to see the full poster(PDF)

If you have any questions, please do not hesitate to contact the Epigraphy.info committee (info@epigraphy.info).